
Part VI: LLMOps: Operating in the Age of Large Language Models
A DevOps Guide to Running Language Models in Production

"LLMOps isn't just MLOps with bigger models - it's about managing systems that think and communicate." - Andrej Karpathy
Remember when microservices felt like a paradigm shift? Today, we're facing a similar transformation with Large Language Models (LLMs). As DevOps engineers, we need to understand how to operationalize these powerful but resource-hungry systems.
Understanding the LLM Revolution
Remember ChatGPT, Gemini, or Nova? These generative AI tools that seem almost magical are powered by Large Language Models (LLMs). As a DevOps engineer, you're probably already using them for code suggestions, documentation, or troubleshooting. Now, imagine being the one who makes these systems run reliably at scale.
The technology behind these AI assistants isn't just about the models - it's about the entire infrastructure that makes them:
🚀 Fast enough to respond in real-time
💾 Smart enough to remember context
📚 Knowledgeable about specific domains
💰 Cost-effective to run in production
The LLMOps Landscape
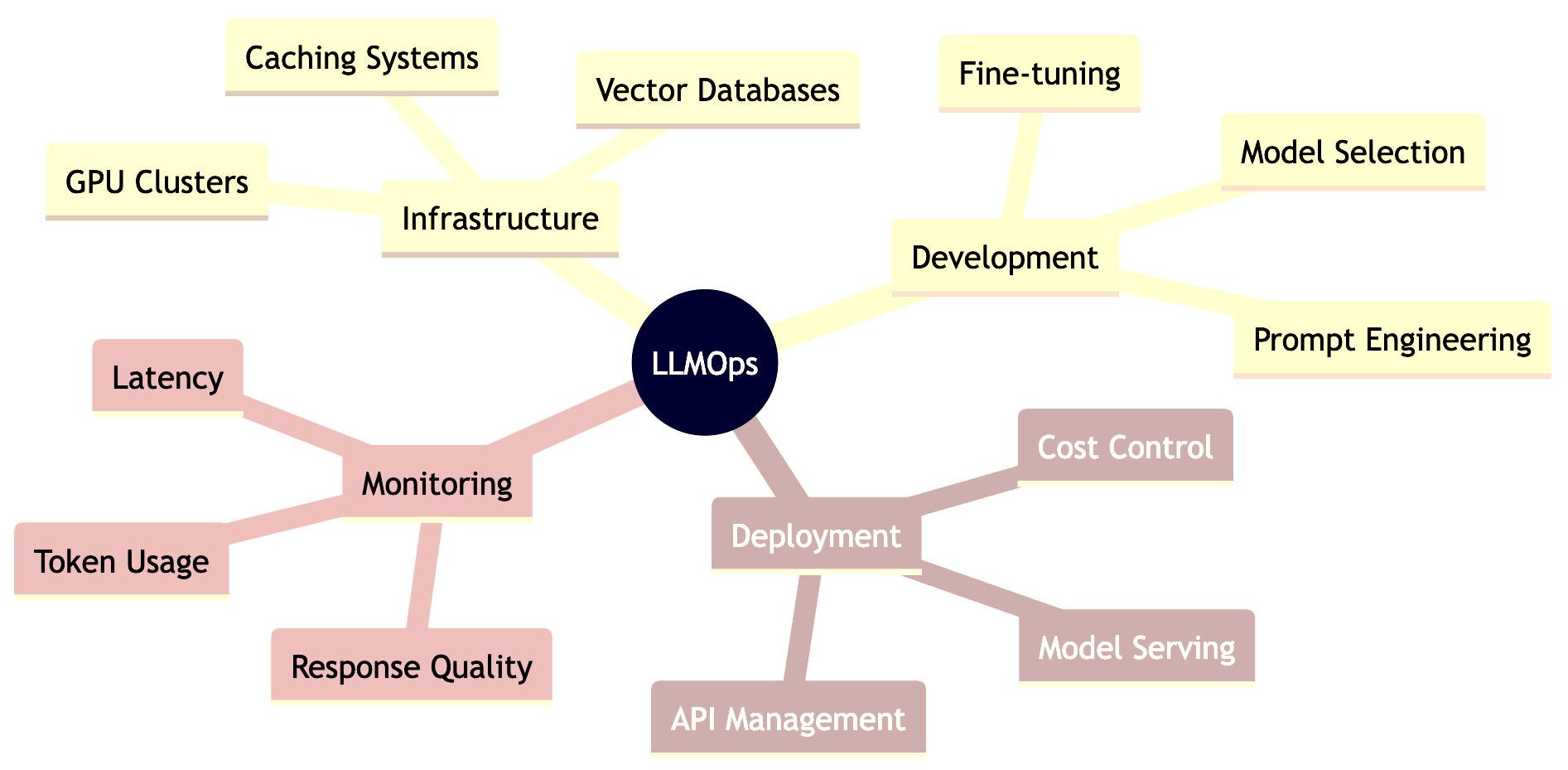
LLMOps Components Explained:
🏗️ Infrastructure: The foundation for LLM operations
🔧 Development: Tools for customizing LLM behavior
🚀 Deployment: Getting models into production
📈 Monitoring: Tracking performance and costs
Core Infrastructure Components
1. Computing Infrastructure
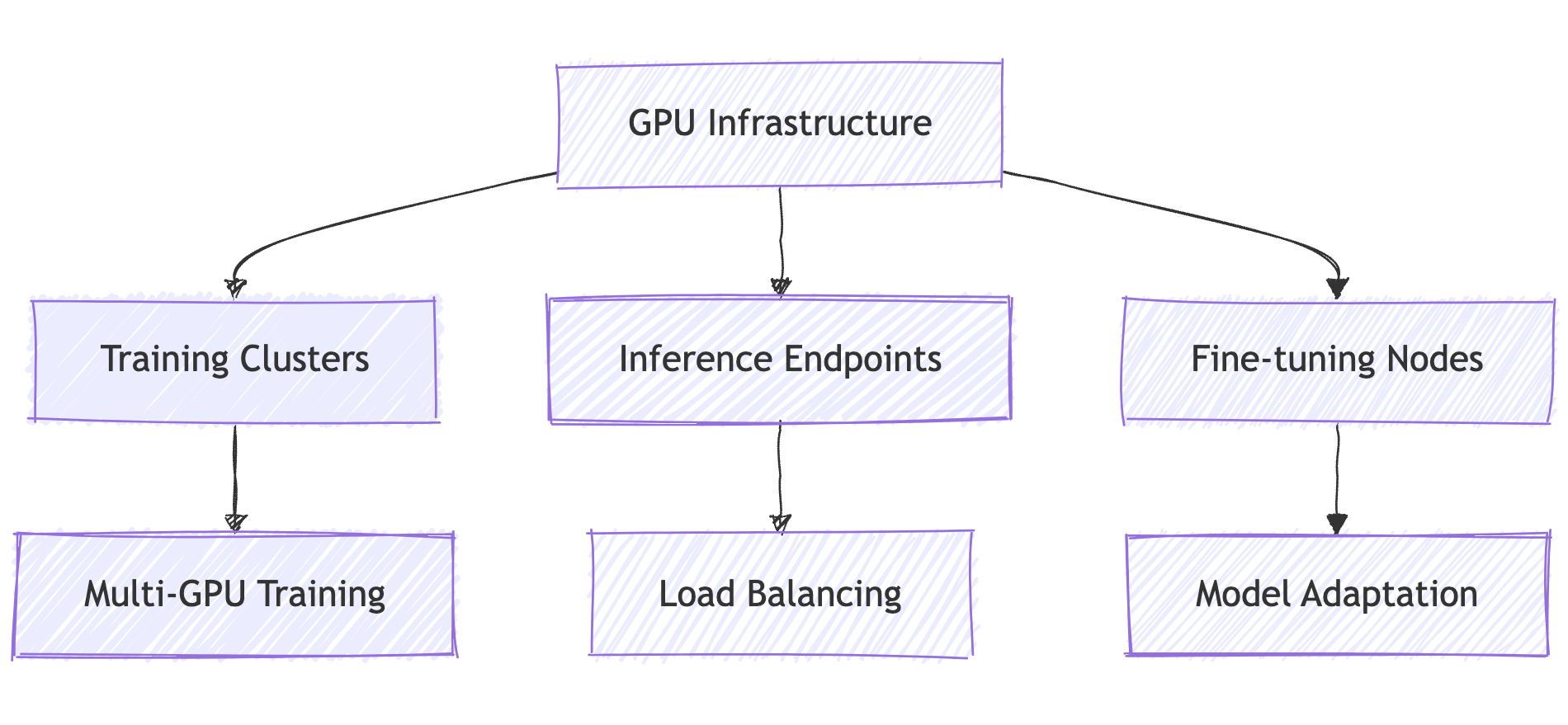
Infrastructure Elements Explained:
🖥️ Training Clusters: For model fine-tuning
⚡ Inference Endpoints: For serving predictions
🔄 Fine-tuning Nodes: For model adaptation
2. Storage and Retrieval
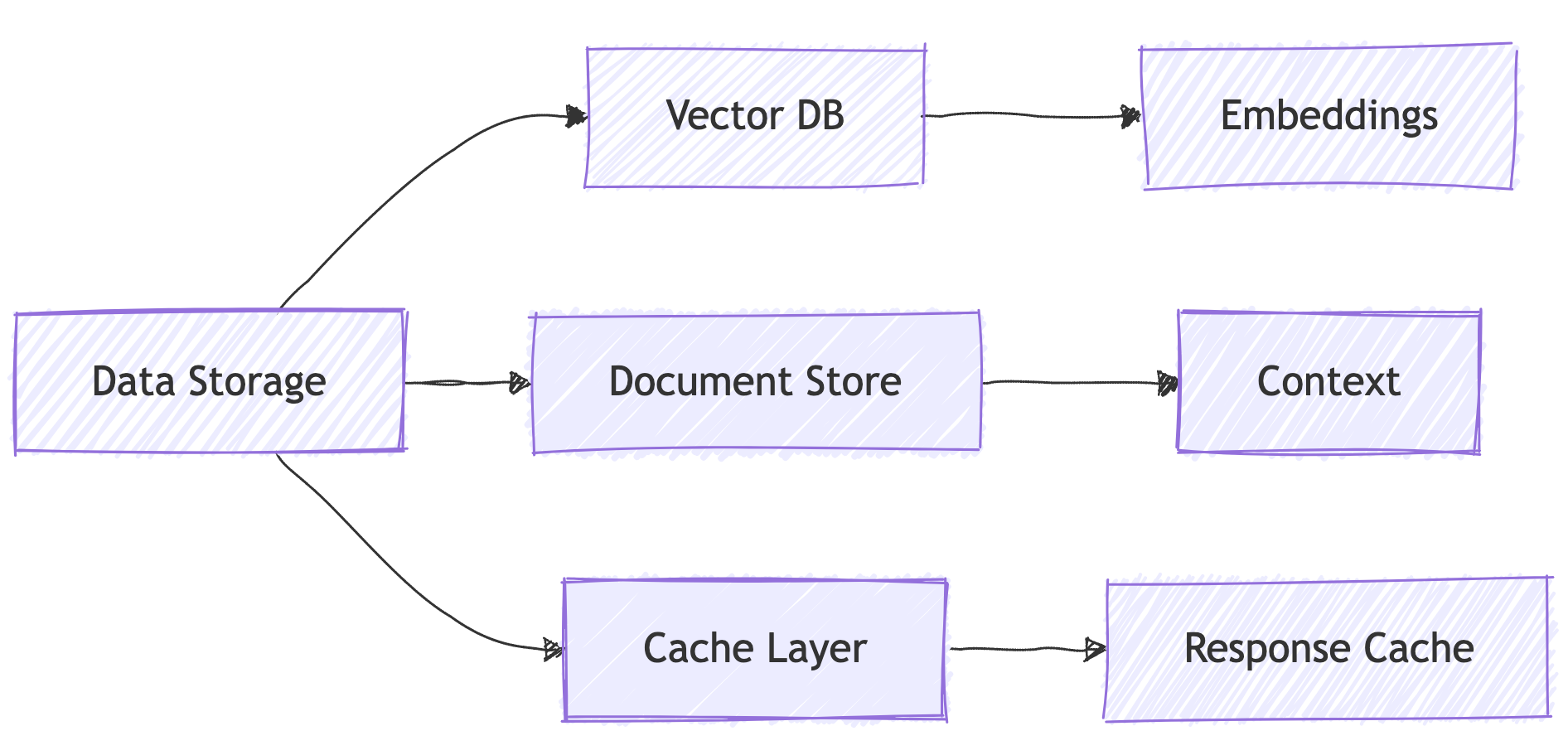
Storage Components Explained:
🗄️ Vector DB: Store and query embeddings
📚 Document Store: Manage context documents
⚡ Cache Layer: Speed up common queries
RAG (Retrieval-Augmented Generation): Making LLMs Smarter
"RAG is like giving your LLM a personalized knowledge base that it can reference before responding."
- Eugene Yan
Think of RAG as a way to give LLMs accurate, up-to-date information without retraining them. Here's why it's crucial:
Why RAG?
🎯 Accuracy: Base LLMs can hallucinate or provide outdated information
📚 Custom Knowledge: Add domain-specific information without fine-tuning
💰 Cost-Effective: Cheaper than retraining or fine-tuning models
🔄 Fresh Data: Easily update information without touching the model
How RAG Works
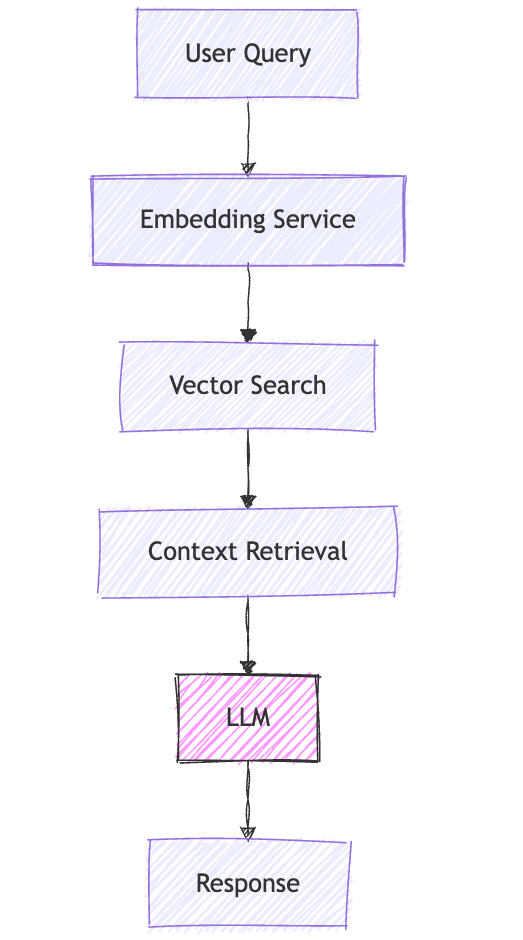
Let's break down the RAG workflow:
📝 User asks a question
🔍 System converts question into a vector (mathematical representation)
🔎 Searches vector database for relevant information
📚 Retrieves matching documents/context
🤖 Sends original question + retrieved context to LLM
✨ Gets more accurate, contextual response
Common RAG Tools
🔵 Vector Databases: Weaviate, Pinecone, Milvus
🔷 Embedding Models: OpenAI Ada, Sentence Transformers
🔶 Integration Frameworks: LangChain, LlamaIndex
Development and Deployment Pipeline
1. LLM Development Workflow
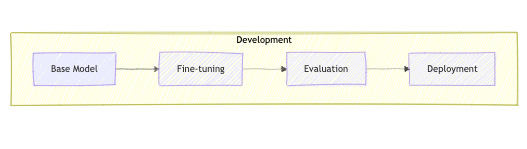
Workflow Explained:
🤖 Base Model: Starting point (e.g., GPT, BERT)
🎯 Fine-tuning: Adapt to specific use case
✅ Evaluation: Test performance and safety
🚀 Deployment: Roll out to production
2. Deployment Patterns
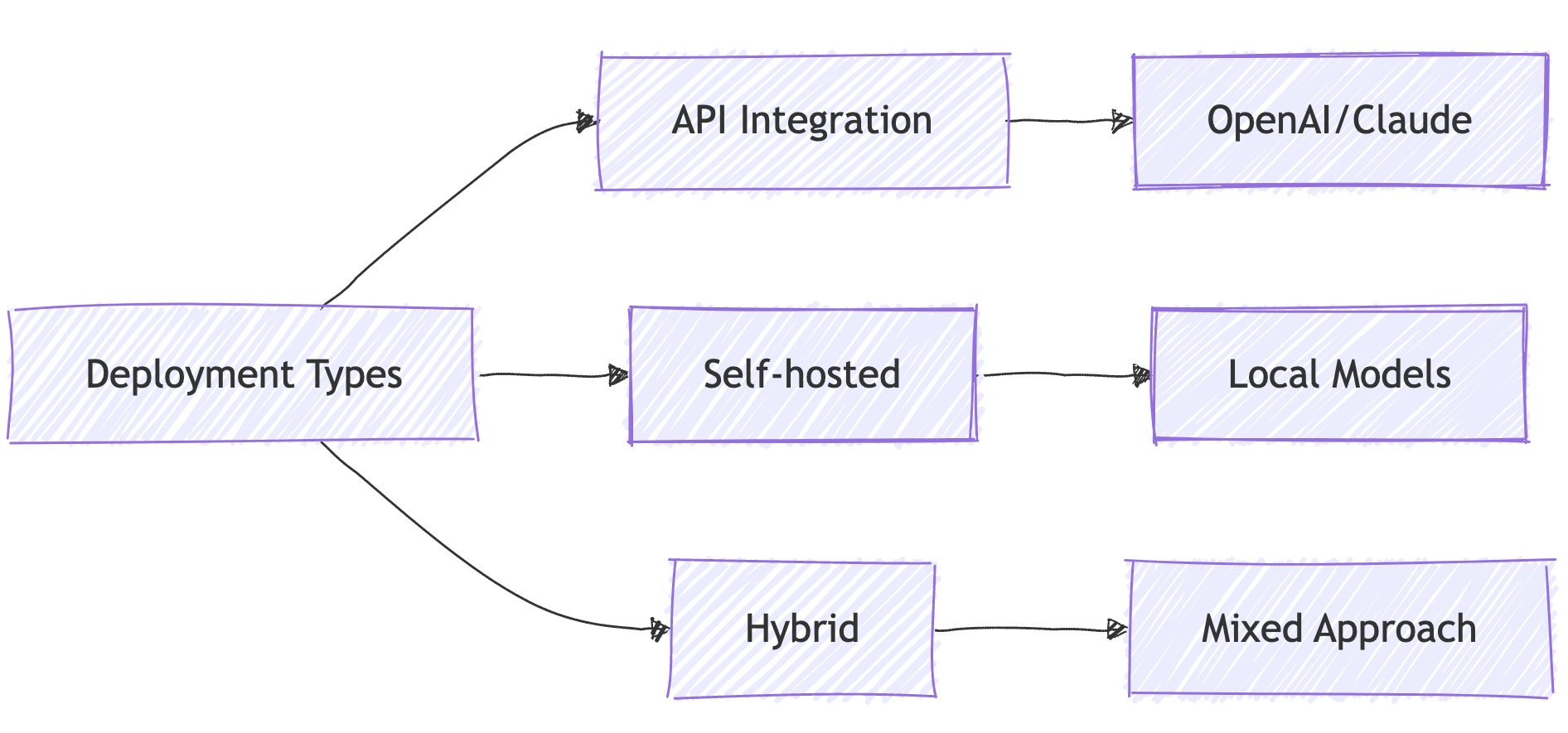
Deployment Options Explained:
🔌 API Integration: Use hosted services
🏠 Self-hosted: Run your own models
🔄 Hybrid: Combine both approaches
Monitoring and Observability
1. Key Metrics
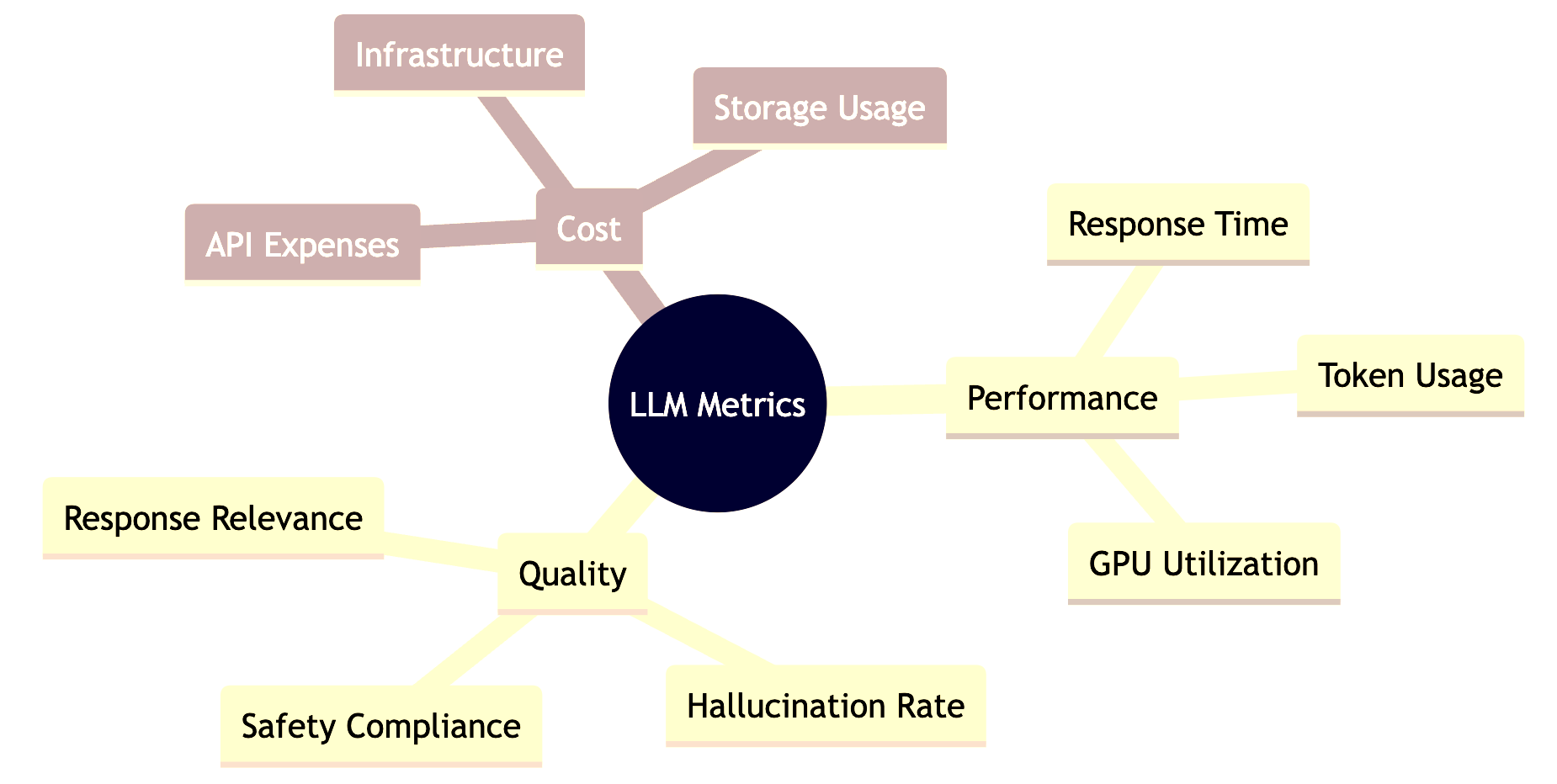
Metrics Explained:
⏱️ Performance: System efficiency
📊 Quality: Response effectiveness
💰 Cost: Resource utilization
2. Monitoring Stack
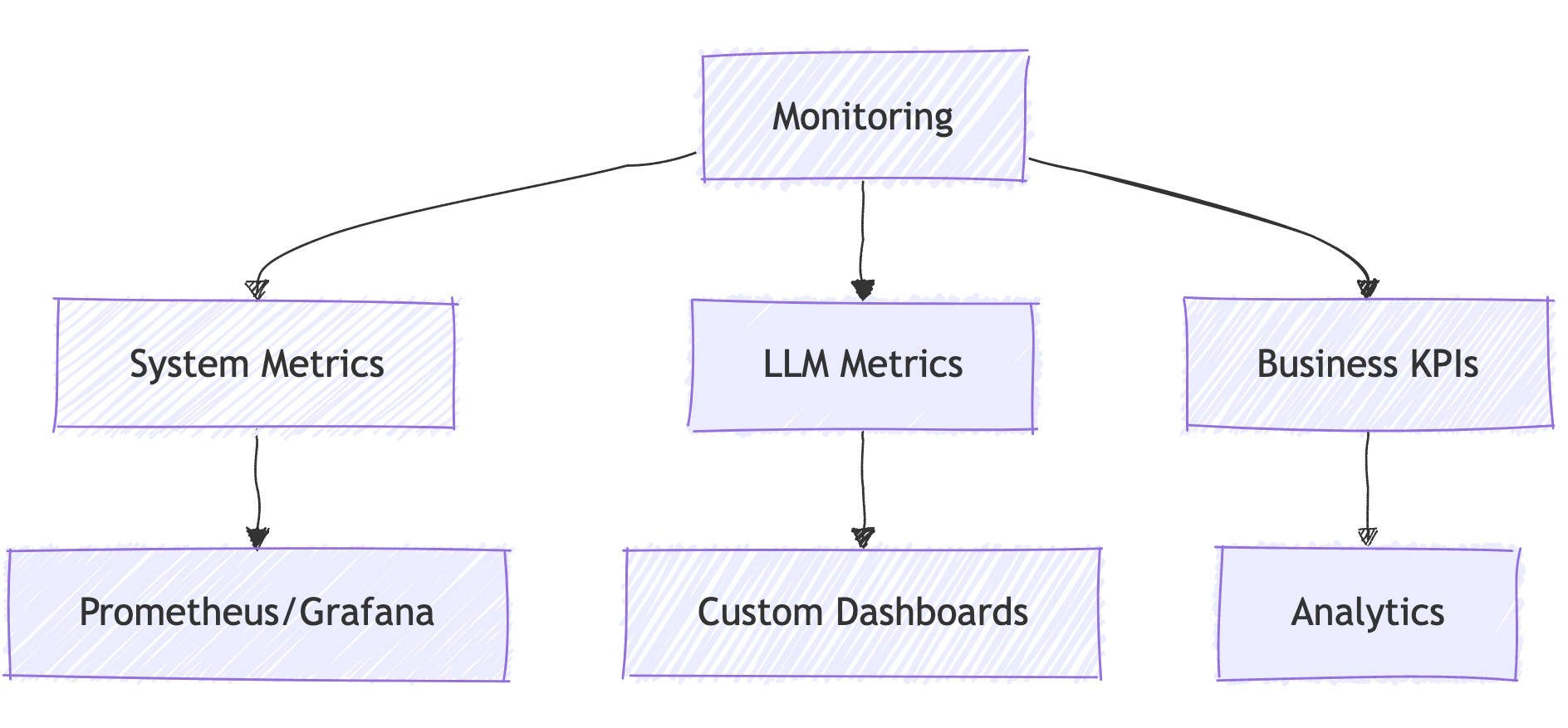
Monitoring Components Explained:
📈 System Metrics: Infrastructure health
🎯 LLM Metrics: Model performance
💼 Business KPIs: Impact metrics
Getting Started with LLMOps
1. Basic Setup (Crawl)
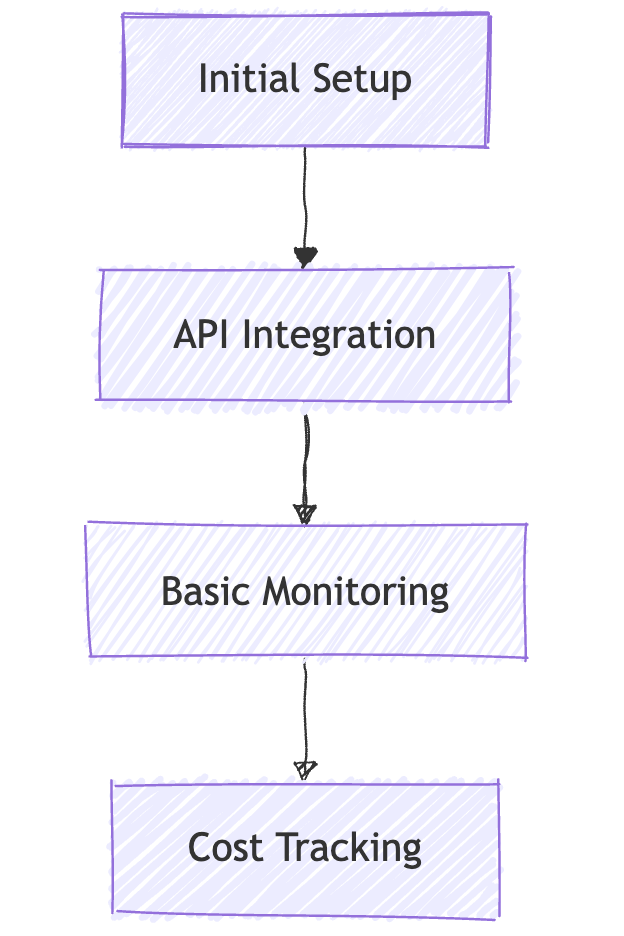
What to Do:
🔌 API Integration: Start with OpenAI/Anthropic APIs
Implement retry logic and error handling
Set up API key management
Create basic prompt templates
📊 Basic Monitoring: Track essential metrics
Response times and success rates
Token usage and costs
Basic error tracking
💰 Cost Tracking: Implement cost controls
Set up usage alerts
Track costs per endpoint/feature
Implement basic caching
2. Advanced Implementation (Walk)
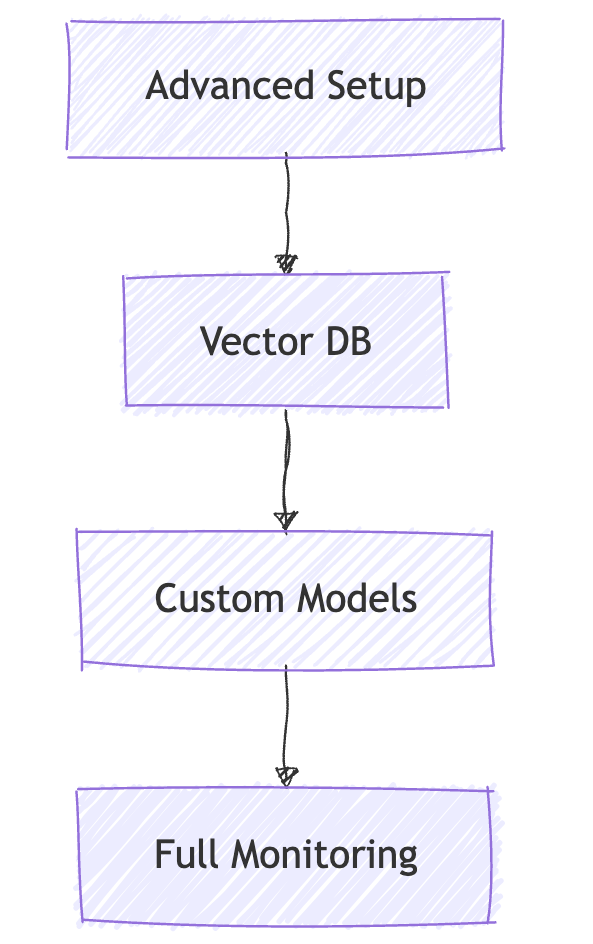
What to Do:
🗄️ Vector DB Setup: Implement RAG
Choose and deploy vector database
Set up document processing pipeline
Implement embedding generation
🤖 Custom Models: Move beyond basic APIs
Deploy open-source models
Implement model fine-tuning
Set up model versioning
📈 Full Monitoring: Comprehensive observability
Response quality metrics
A/B testing framework
Advanced analytics
3. Full Scale (Run)
🏗️ Infrastructure: Production-grade setup
GPU cluster management
Multi-region deployment
High availability architecture
🔄 Automation: Streamlined operations
Automated deployment pipelines
Self-healing systems
Continuous evaluation
📊 Advanced Features: Enhanced capabilities
Multi-model orchestration
Automated cost optimization
Advanced security features
Common Challenges and Solutions
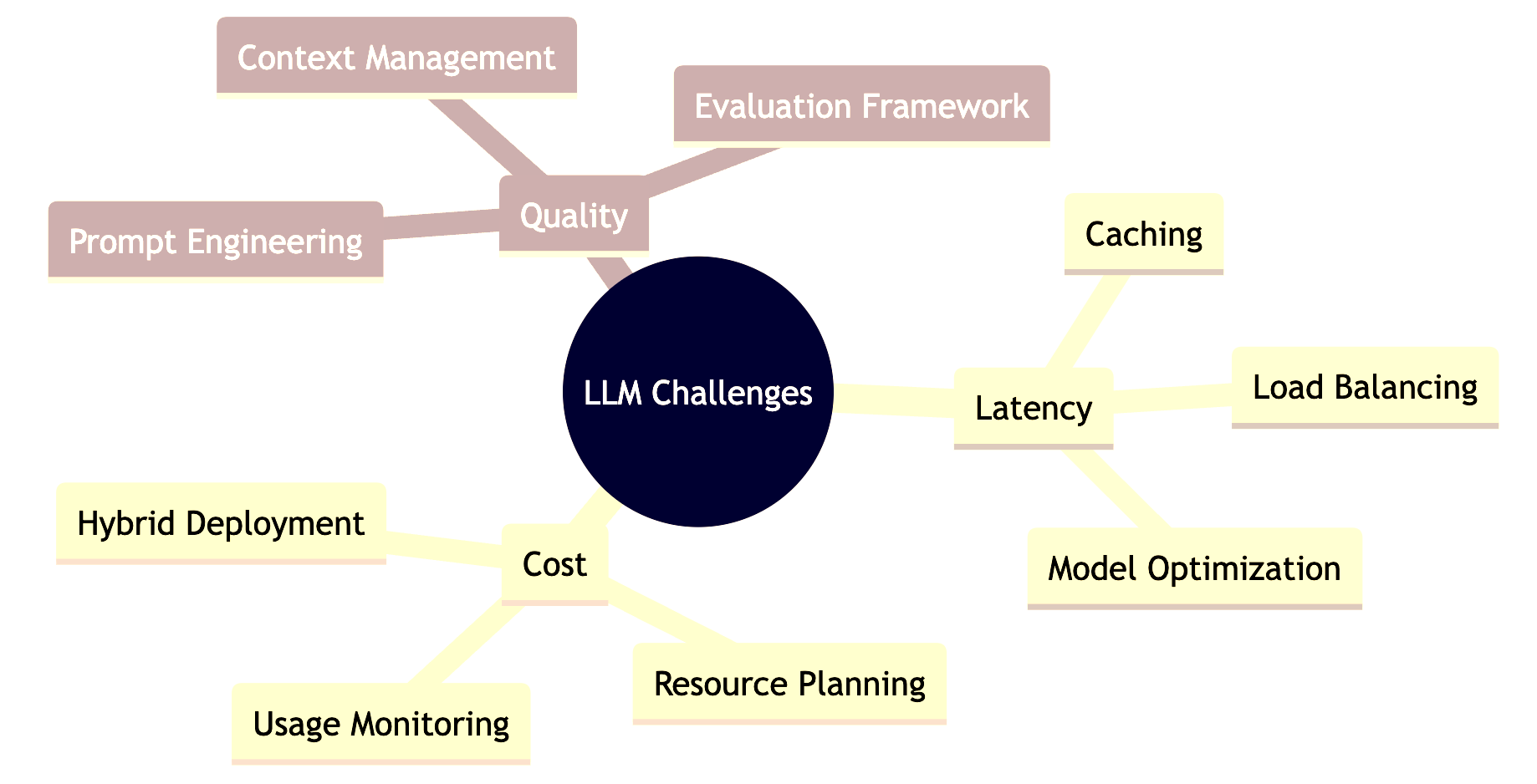
Key Takeaways
Start Simple: Begin with managed services
Monitor Everything: Track costs and performance
Optimize Gradually: Improve based on usage patterns
Plan for Scale: Design for growth from the start
"The key to successful LLMOps is finding the right balance between capability and complexity."
- Chip Huyen
What's Next?
In our next article, "Career Paths: From DevOps to MLOps," we'll explore how to build your career in AI operations, including the skills, certifications, and experience you'll need.
Series Navigation
📚 DevOps to MLOps Roadmap Series
Series Home: From DevOps to AIOps, MLOps, LLMOps - The DevOps Engineer's Guide to the AI Revolution
Next: The New World of ML Infrastructure: A DevOps Engineer's Guide
💡 Subscribe to the series to get notified when new articles are published!