
Part VII - The New World of ML Infrastructure
From Container Orchestration to AI Systems: A DevOps Engineer's Guide

"It's just infrastructure - but with different workloads and requirements."
- Kelsey HightowerRemember when we moved from running apps on VMs to containers? The principles stayed the same, but the tools and patterns changed. That's exactly what's happening with ML infrastructure. As a DevOps engineer, you already know 80% of what's needed - let's explore the 20% that's different.
What Are We Really Talking About?
Let's break this down into familiar terms:
Understanding Different ML Infrastructure Types
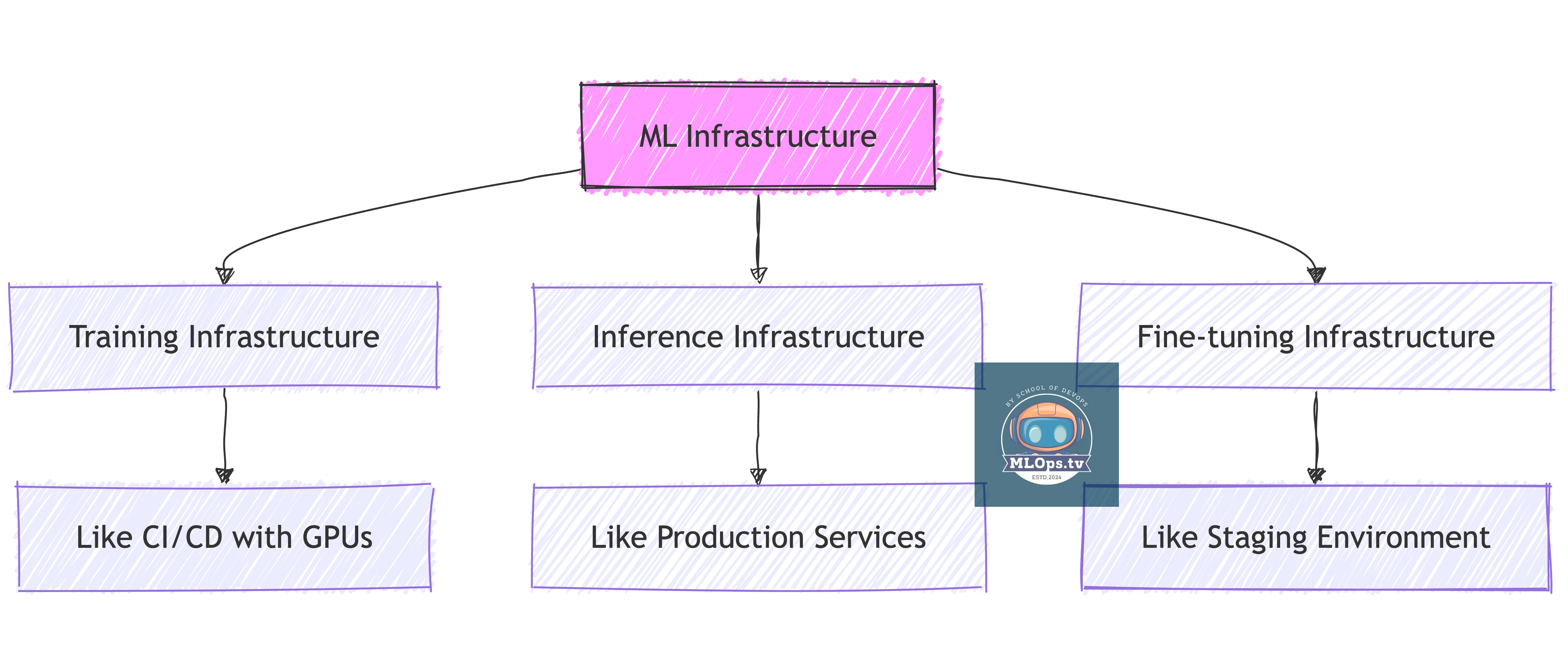
Type 1: Training Infrastructure
Think of this as your "build system" for ML models:
🏗️ Like your CI/CD build servers (note : we are only referring to infra, there is no CI/CD involved in model training) but with GPUs
🚀 Heavy resource usage but temporary
💡 Example: What OpenAI uses to train GPT models
⚠️ Not something most of us will build
Type 2: Inference Infrastructure
This is your "production environment" for ML:
🔄 Like running microservices but with specific requirements
📊 Consistent, predictable resource usage
💡 Example: Systems running ChatGPT or Claude
✅ What most of us will actually work with
Type 3: Fine-tuning Infrastructure
Think of this as your "customization environment":
🔧 Like staging environments where you modify existing apps
📈 Moderate resource usage
💡 Example: Adapting LLMs for specific use cases
✅ What many organizations need
What You Already Know That Applies
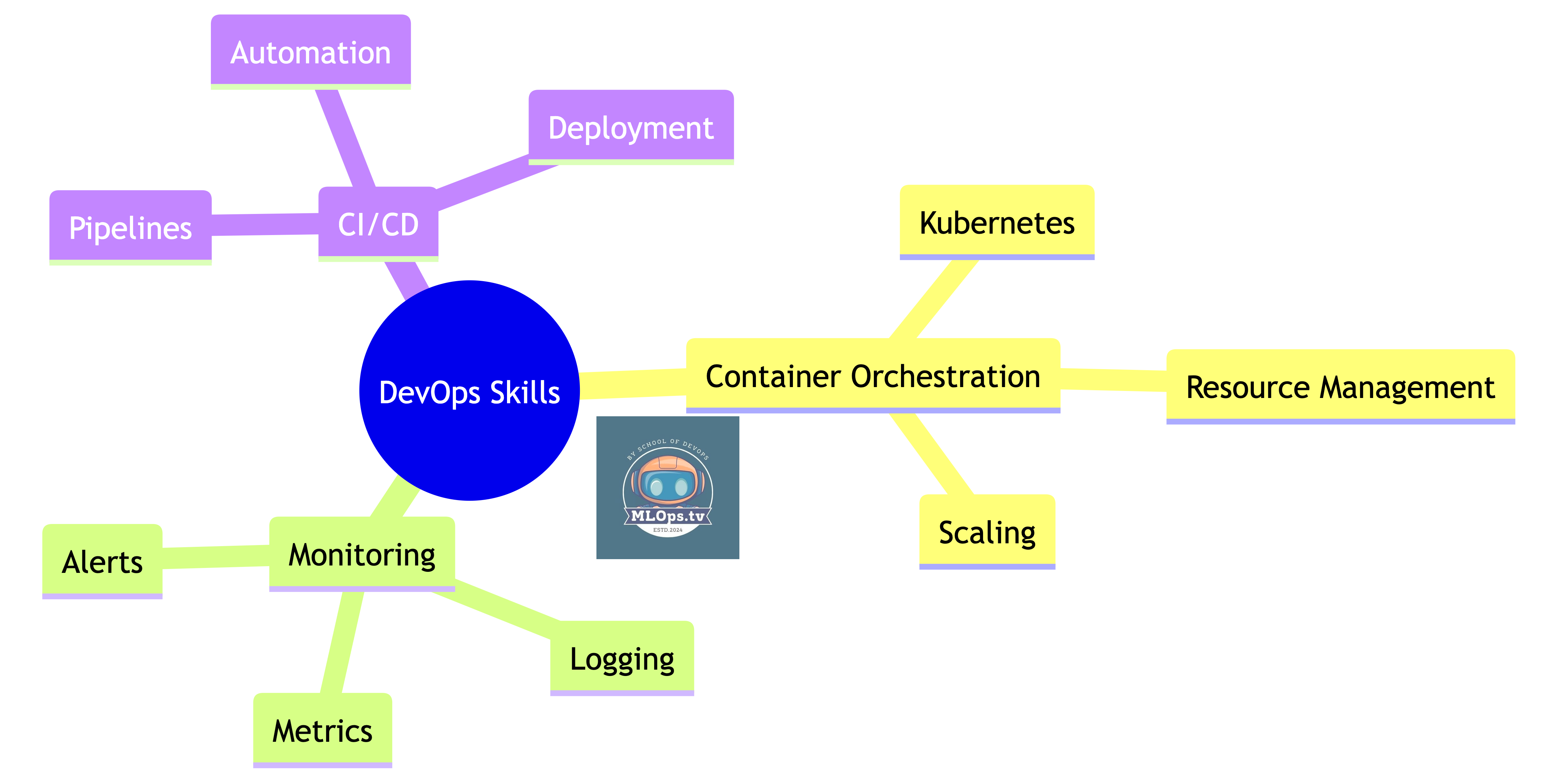
Your Transferable Skills:
🎯 Kubernetes management
📊 Monitoring and observability
🔄 CI/CD pipeline creation
🚀 Scalability patterns
🔒 Security practices
What's Different with ML Workloads
1. Resource Management
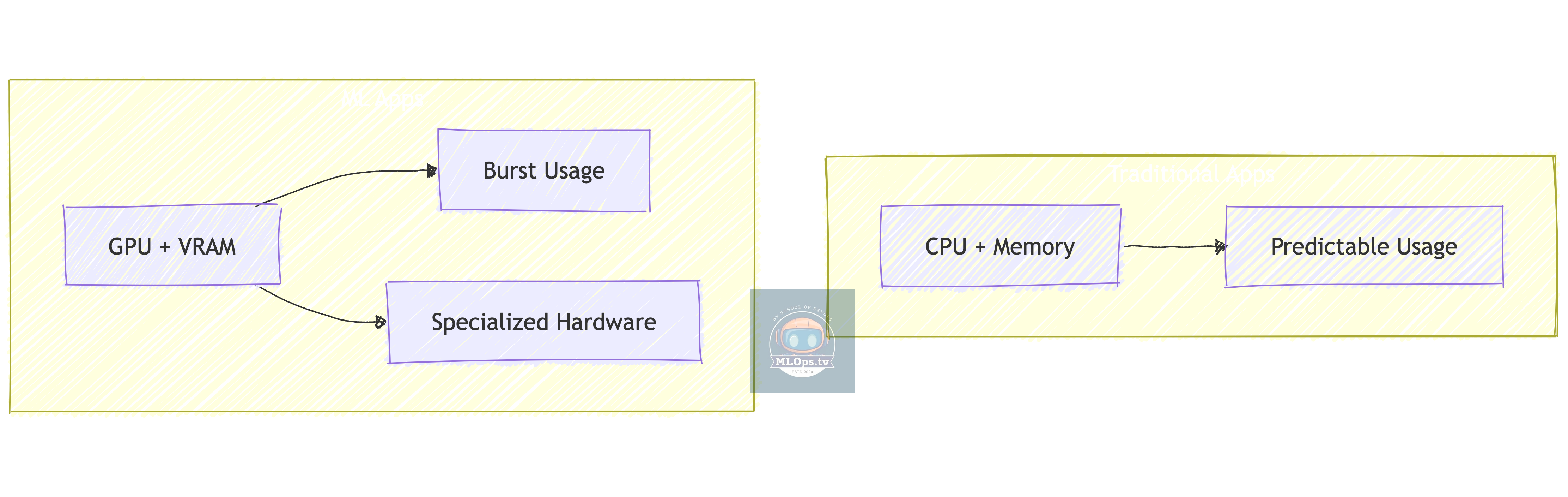
Key Differences:
🎮 GPU management instead of just CPU/RAM
💾 Much larger storage requirements
🔄 Bursty workload patterns
💰 Different cost optimization needs
2. Deployment Patterns
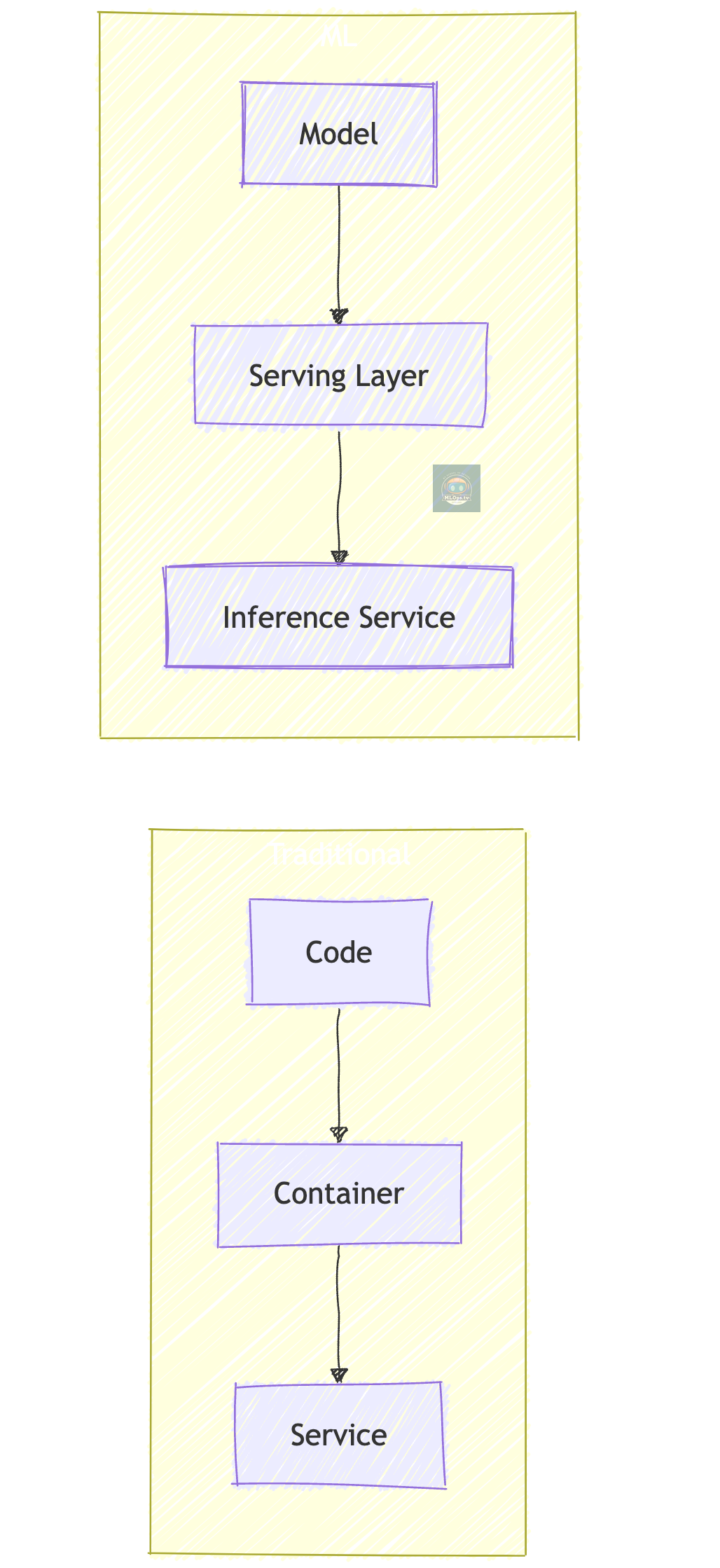
What's Different:
📦 Model artifacts instead of code
🚀 Specialized serving frameworks
🔄 Different scaling patterns
📊 Different metrics to monitor
What You'll Actually Build
1. Basic ML Service Infrastructure
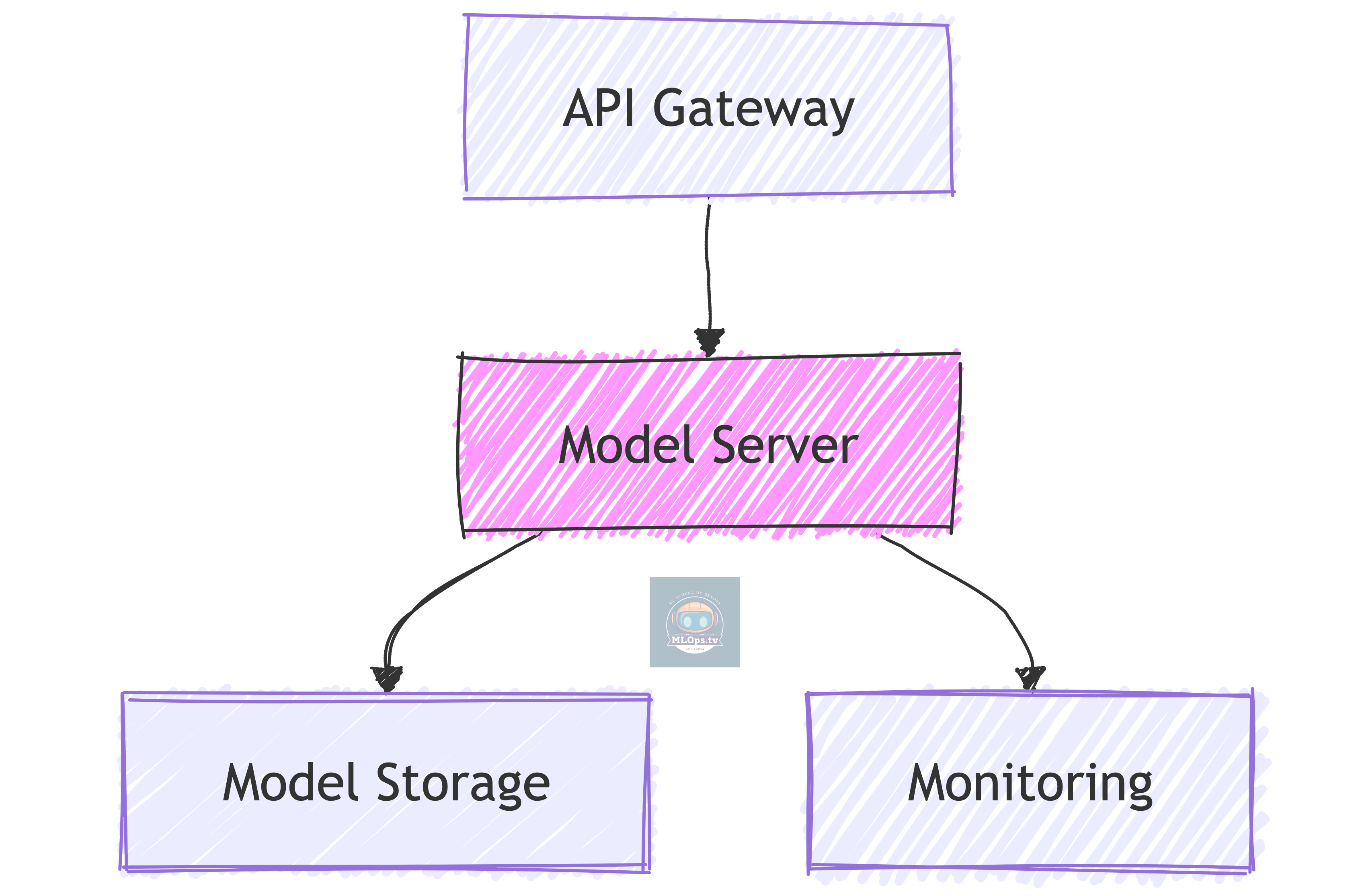
Just Like Microservices, But:
🎯 Uses specialized model servers
💾 Needs efficient model storage
📊 Requires ML-specific monitoring
🔄 Different scaling triggers
2. GPU-Enabled Kubernetes Cluster
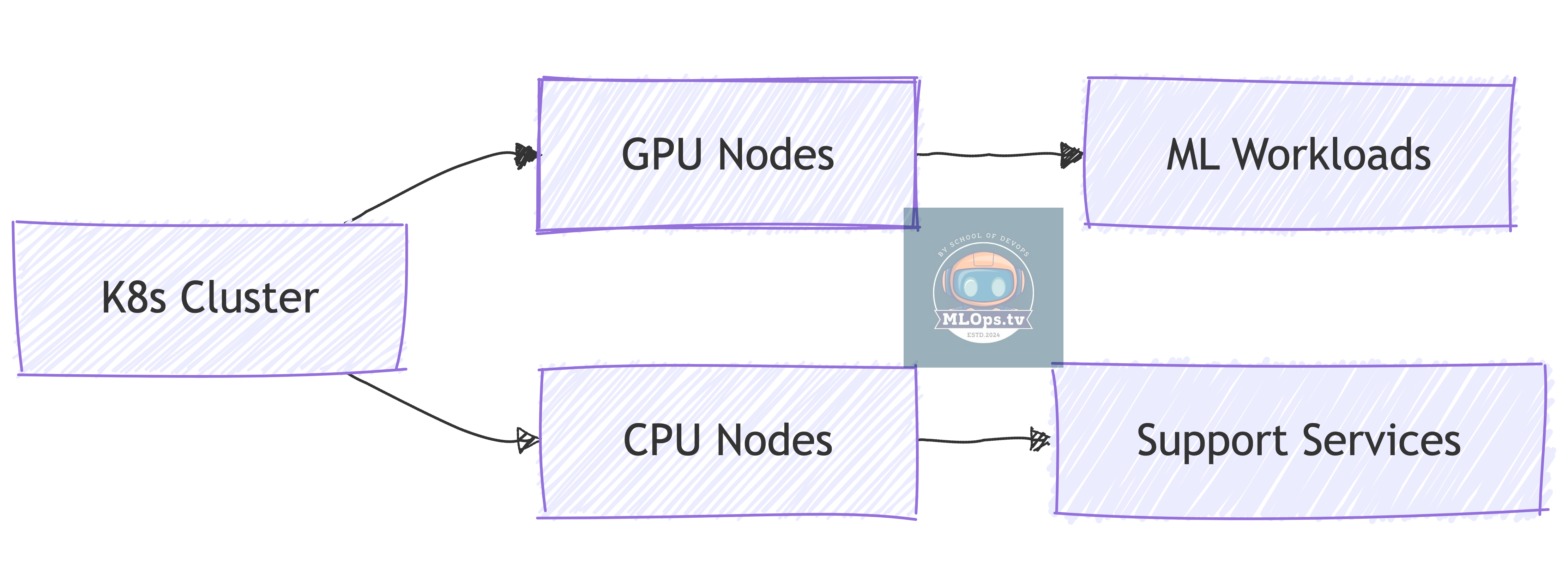
What You Need to Know:
🎮 GPU operator setup
🔧 Node labeling for GPU workloads
📊 GPU monitoring
💰 Cost optimization
3. Model Serving Pipeline
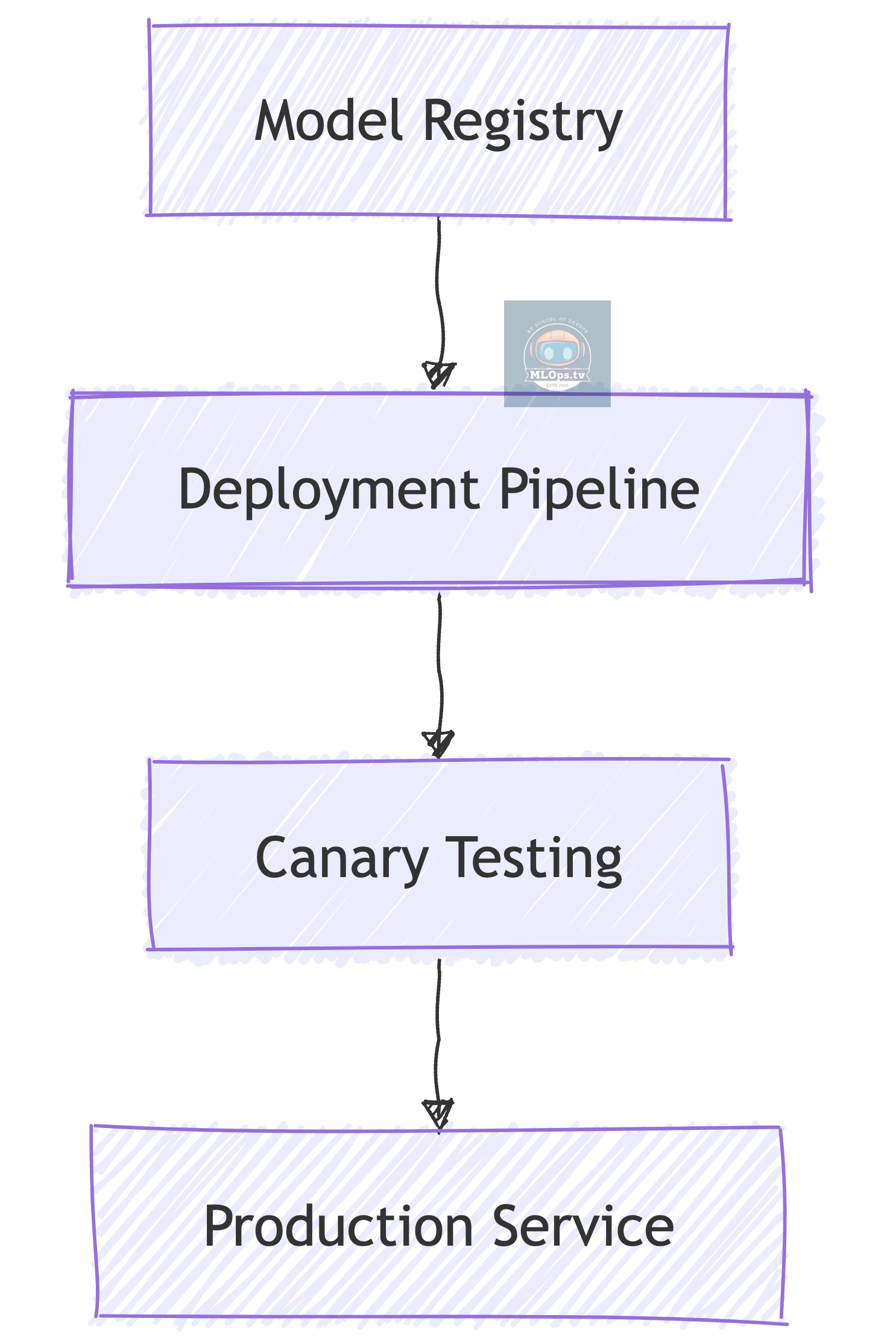
Similar to App Deployment, But:
📦 Model versioning in addition to code versioning
🔄 Different rollout patterns
📊 Different health checks
🎯 Different scaling metrics
Practical Starting Point
1. Start with CPU-Only ML Services
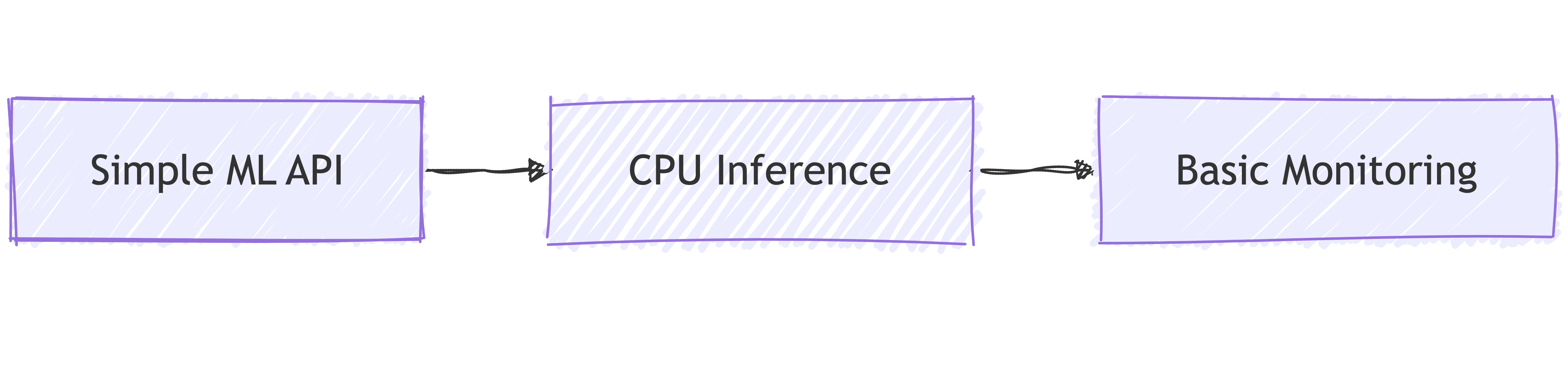
Why Start Here:
🎯 Familiar territory
📊 Learn ML patterns
💰 Lower cost
🔧 Simpler setup
2. Graduate to GPU Workloads

Natural Progression:
🎮 Learn GPU management
📈 Understand scaling
💰 Optimize costs
🔧 Handle complexity
Common Pitfalls to Avoid
Over-Engineering
🎯 Start simple
📈 Scale when needed
💰 Control costs
Wrong Focus
✅ Focus on serving patterns
❌ Don't build training infrastructure yet
🎯 Solve real problems
Ready to Start Building?
Join our upcoming cohort to learn ML infrastructure the DevOps way:
🎯 Register here for the next available cohort
📚 Get hands-on with ML infrastructure
👥 Learn from experienced practitioners
🚀 Build production-ready systems
"The best ML infrastructure is the one that feels familiar to operate."
Series Navigation
📚 DevOps to MLOps Roadmap Series
Series Home: From DevOps to AIOps, MLOps, LLMOps - The DevOps Engineer's Guide to the AI Revolution
Previous: LLMOps: Operating in the Age of Large Language Models
💡 Ready to build ML infrastructure? Register now for the next available cohort!
#aa-MLOps/roadmapseries