
Updating ML Models in Production: The Strategic Dance Between Model and Data Iteration

As an AI/ML Engineer with years of experience deploying and maintaining production systems, I’ve learned that successful model updates require a nuanced understanding of when to iterate on your model architecture versus when to focus on refreshing model with new data. Let’s dive deep into these strategies and why you need both in your MLOps toolkit.
The Production Update Challenge
Updating machine learning models in production isn’t just about swapping out pickle files. It’s a complex orchestration of technical decisions, risk management, and strategic thinking that can make or break your ML system’s performance and reliability.
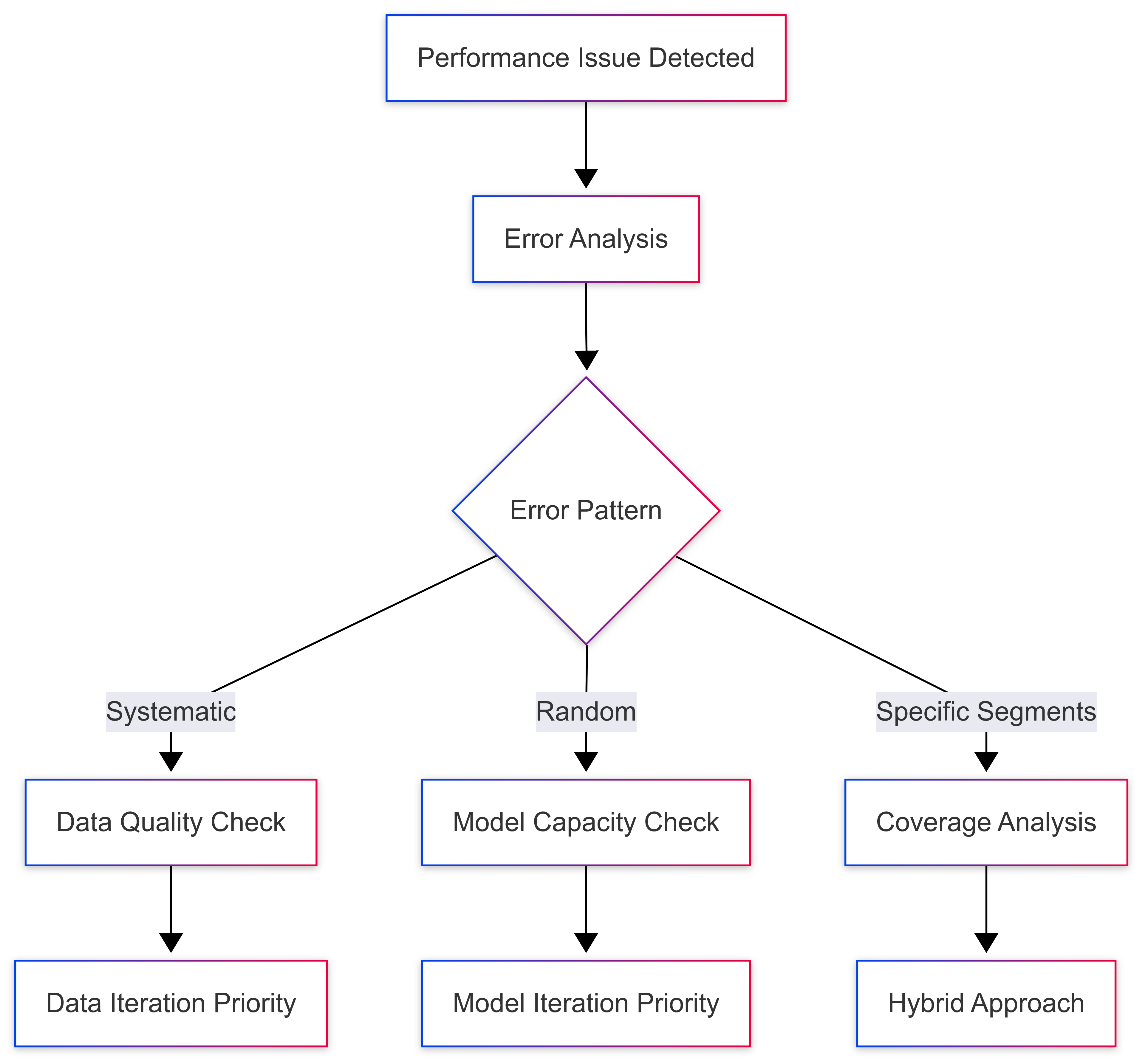
Model Iteration: When Architecture Matters
Model iteration involves updating the underlying algorithm, architecture, or hyperparameters while keeping your training data relatively constant. Think of it as upgrading your engine while using the same fuel.
When to Choose Model Iteration
1. Performance Plateaus: When additional data shows diminishing returns, but you suspect your model architecture is the bottleneck.
2. New Algorithmic Advances: When state-of-the-art models in your domain show significant improvements over your current approach.
3. Computational Constraints: When you need to optimize for inference speed, memory usage, or energy efficiency.
4. Feature Engineering Insights: When domain expertise reveals new ways to structure or represent your problem.
Model Iteration Advantages
Immediate Impact: Architectural improvements can yield dramatic performance gains
Resource Efficient: Doesn’t require new data collection or labeling
Controlled Environment: Changes are deterministic and reproducible
Technical Debt Reduction: Opportunity to modernize legacy architectures
Model Iteration Disadvantages
Limited by Data Quality: Can’t fix fundamental data issues
Overfitting Risk: More complex models may memorize training data
Integration Complexity: New architectures may require infrastructure changes
Validation Overhead: Extensive testing needed to ensure production compatibility

Data Iteration: When Information is Power
Data iteration focuses on improving, expanding, or refining your training dataset while maintaining your model architecture. It’s like upgrading your fuel quality and supply while keeping the same engine.
When to Choose Data Iteration
Concept Drift: When your model’s assumptions about the world are becoming outdated
Underrepresented Scenarios: When production reveals edge cases not covered in training
Data Quality Issues: When you identify systematic biases, errors, or inconsistencies
Domain Expansion: When you need to handle new use cases or user segments
Data Iteration Advantages
Addresses Root Causes: Fixes fundamental data quality and coverage issues
Improves Generalization: Better data diversity leads to more robust models
Lower Technical Risk: Same model architecture reduces deployment complexity
Business Alignment: New data often reflects changing business needs
Data Iteration Disadvantages
Time Intensive: Data collection, cleaning, and labeling take significant time(If not automated data pipeline is built for upstream data)
Resource Heavy: Requires substantial human and computational resources(If not followed stateful training and every time retraining from scratch)
Quality Control: Ensuring new data maintains consistency standards is challenging
Diminishing Returns: Additional similar data may not improve performance
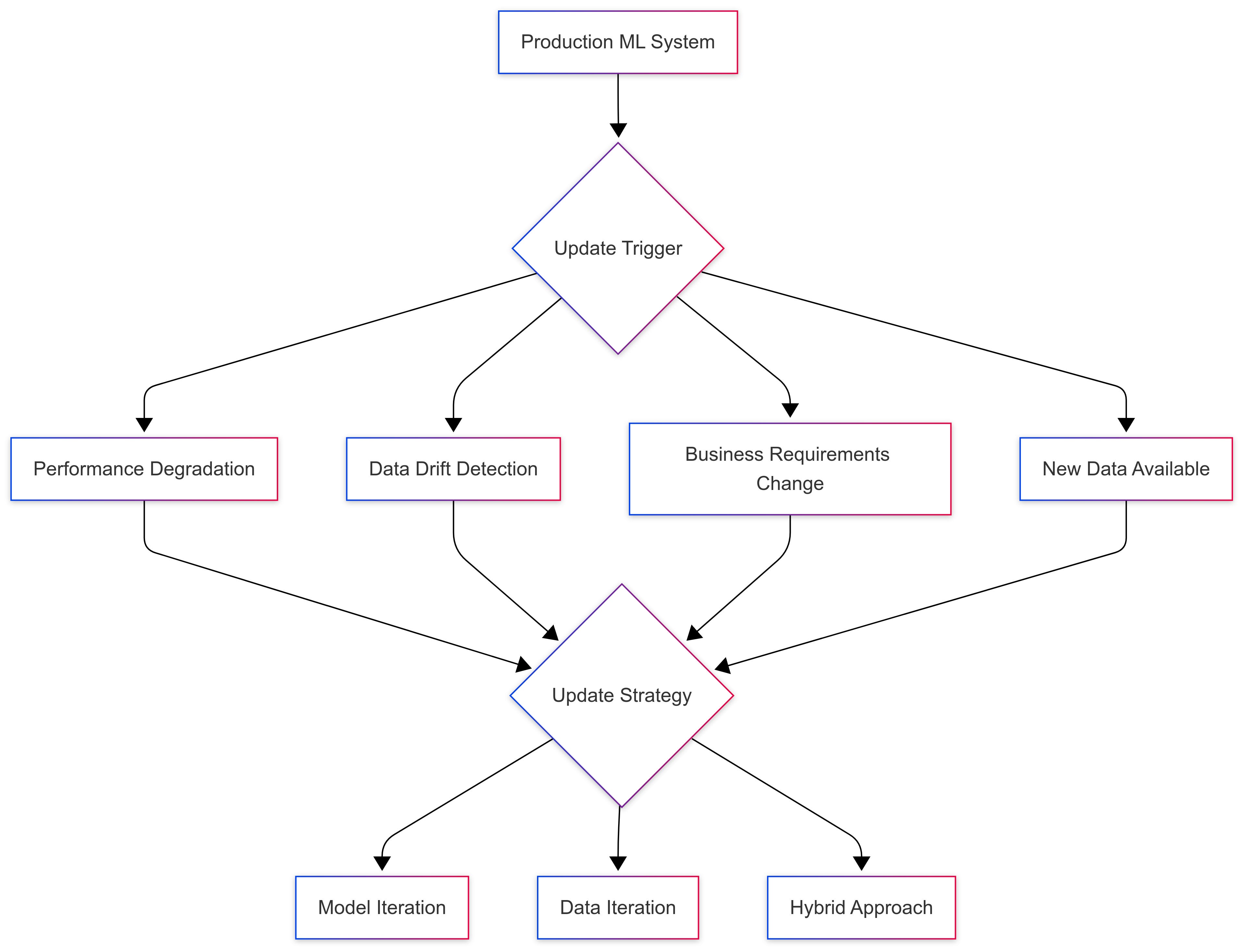
The Strategic Framework: When to Do What
In practice, you should do both from time to time. However, the more resources you spend in one approach, the fewer resources you can spend in another.
If you find that iterating on your data does not give you much performance gain, then you should spend your resources on finding better model. On the other hand, if finding a better model architecture requires 100X compute for training and gives you 1% performance whereas updating the same model on fresh data which requires 1X compute and gives same 1% performance gain, you will be better off iterating on data.
Below is decision framework for production model updates I have used. Off course, a lot depends on business requirements and other factors.
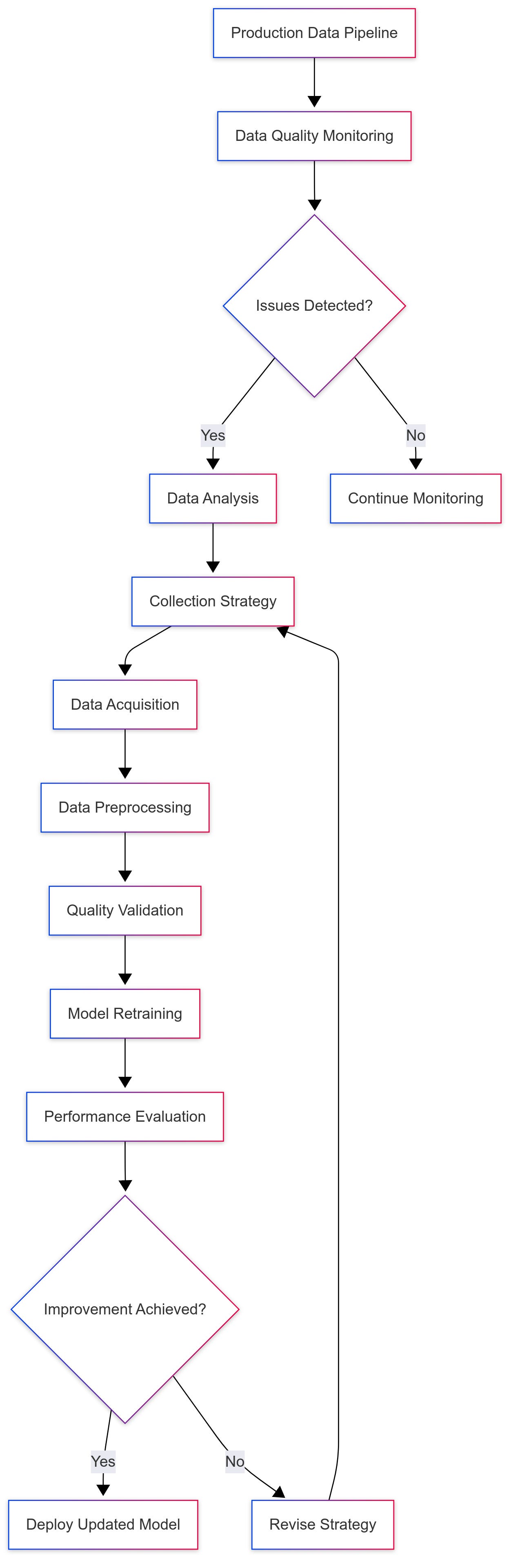
The Hybrid Approach: Best of Both Worlds
In practice, the most successful production systems employ both strategies in a coordinated manner: One example is below
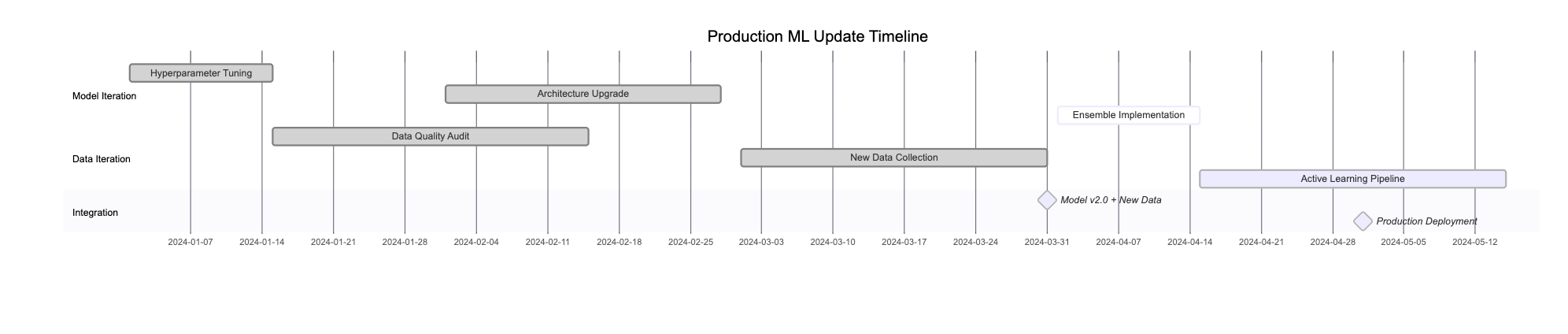
Production Implementation Best Practices
Monitoring and Rollback
Implement comprehensive model performance dashboards
Set up automated alerts for drift detection
Maintain rollback capabilities with previous model versions
Use feature flags for quick model switching
Documentation and Versioning
Track data lineage and model provenance
Document all architectural changes and their rationale
Maintain reproducible training pipelines
Version control both code and data schemas
Gradual Rollout Strategy
There is always risk associated with deploying models to production that haven’t been sufficiently evaluated. Evaluation is mixture of offline and online methods. The fact that model does well on test data, will not guarantee it will do well in production, the only way to ensure it is to deploy it in production, I know it’s scary but there are techniques to help us evaluate models in production. Below covers some of them, I will try to cover this topic in more detail in another blog.

Conclusion: The Strategic Imperative
Updating production ML models isn’t an either/or decision between model and data iteration — it’s about understanding when each approach provides maximum value and how they complement each other.
Key Takeaways :
Start with diagnostics: Understand the root cause before choosing your strategy
Plan for both: Build infrastructure that supports both model and data iteration
Measure everything: Comprehensive monitoring enables data-driven decisions
Think in cycles: Successful ML systems require ongoing iteration, not one-time updates
The most resilient production ML systems treat model updates as an ongoing strategic capability, not a reactive fire-fighting exercise. By mastering both model and data iteration strategies, you’ll build systems that not only perform well today but adapt and improve over time.
Remember: Your production ML system is only as good as your ability to evolve it. Plan for change, and change will become your competitive advantage.