
MLOps Workflow, Components, and Key Practices
Part 1: Devops to MLOps, how do you map the workflow, skills and understand the key practices at a high level.

"The best MLOps engineers I've worked with didn't start as ML experts - they were DevOps engineers who understood how to operationalize complex systems."
-- David Aronchick, former Kubernetes Lead at Microsoft

How to Use This Conceptual Guide
Welcome to Part 1 of our MLOps learning series! As a DevOps engineer, you already understand complex operational systems. This guide will help you extend that knowledge into the world of machine learning operations.
What This Guide Is:
✅ A conceptual overview of MLOps development environments
✅ A bridge between your DevOps knowledge and ML operations
✅ A foundation for understanding MLOps principles
✅ A guide to key tools and concepts you'll encounter
What This Guide Isn't:
❌ A hands-on tutorial
❌ A complete implementation guide
❌ A deep dive into ML algorithms
Throughout this guide, you'll see code snippets and diagrams. Think of these as learning aids - they're meant to illustrate concepts and help you understand the principles, not to be copied directly into production. Just as you might sketch out a system architecture to understand it better, these examples help visualize MLOps concepts.
💡 Learning Approach:
We'll build on your DevOps expertise, drawing parallels between concepts you already know and their MLOps counterparts. This approach helps you leverage your existing knowledge while learning new concepts.
How MLOps Builds on Your DevOps Skills
As a DevOps engineer, you've mastered the art of automating, deploying, and managing applications. This experience gives you a unique advantage in the world of MLOps. Let's explore how your existing skills translate to this new domain:
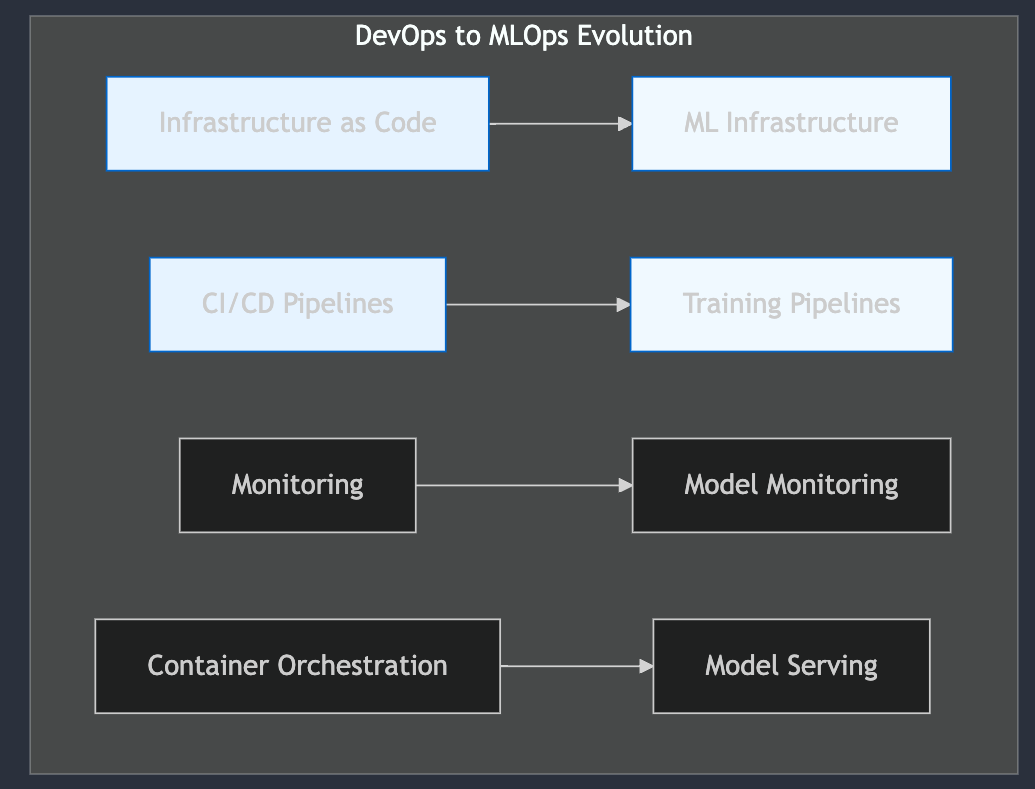
Let's break down each transition shown in this diagram:
Infrastructure as Code → ML Infrastructure
Your experience with IaC tools like Terraform gives you a solid foundation. In MLOps, you'll apply these same principles while adding ML-specific resources:
GPU-enabled compute clusters for training (think EC2 instances with GPUs)
Specialized storage for large datasets (like S3 buckets optimized for ML workloads)
Model serving infrastructure (similar to application servers, but optimized for inference)
Feature stores and experiment tracking systems (new concepts unique to ML)
CI/CD Pipelines → Training Pipelines
Your pipeline expertise evolves to handle ML workflows:
Instead of compiling code, you're training models
Rather than unit tests, you have data validation
Beyond deployment checks, you need model performance validation
Continuous integration becomes continuous training
Monitoring → Model Monitoring
Your monitoring skills extend to new dimensions:
Traditional metrics (CPU, memory, latency) remain crucial
New ML-specific metrics (model accuracy, prediction quality)
Data quality and drift detection (is your model's world changing?)
Container Orchestration → Model Serving
Your Kubernetes knowledge applies directly, with some new considerations:
GPU resource management
Model deployment strategies
Scaling for inference workloads
Understanding the MLOps Workflow
In traditional DevOps, you manage the journey from code to production. MLOps adds data and models to this equation, creating a more complex but manageable workflow:

Let's examine key components of this workflow in detail:
Data + Code
Unlike traditional applications where code is your primary input, ML systems depend equally on code and data. Think of data as another form of source code - changes in either can affect your system's behavior:
Code changes (model architecture, training logic)
Data changes (new training examples, updated features)
Configuration changes (hyperparameters, preprocessing steps)
Training
This step is analogous to your build process in DevOps, but with key differences:
More resource-intensive than traditional builds
Less deterministic (same inputs might give slightly different results)
Longer running (hours or days vs minutes)
Validation
While in DevOps you run unit tests and integration tests, ML validation includes:
Model performance metrics (accuracy, precision, recall)
Data quality checks
Bias and fairness assessments
Resource utilization validation
Key Components of MLOps
Let's explore the essential building blocks of an MLOps environment. As a DevOps engineer, you'll find many parallels to your existing tools, along with some new concepts specific to ML systems.
1. Data Version Control
Think about how Git revolutionized code collaboration. Data version control does the same for ML datasets. Here's what this looks like in practice:

This diagram shows how data versioning works in an MLOps environment. Let's break down the components:
Raw Data to Versioned Dataset
Just as your application code goes through transformations before deployment, raw data needs preprocessing:
# Conceptual example of data versioning workflow
dvc add data/raw/customer_data.csv # Version raw data
dvc run -n preprocess # Run and track preprocessing
python preprocess.py # Transform data
dvc add data/processed/features.csv # Version processed dataThe key difference from traditional version control:
Handles large files efficiently (unlike Git)
Tracks data transformations
Maintains reproducibility
Connects data versions to model versions
2. Experiment Tracking
If you've used Jenkins or GitLab CI to track builds, experiment tracking will feel familiar, but with an ML focus:
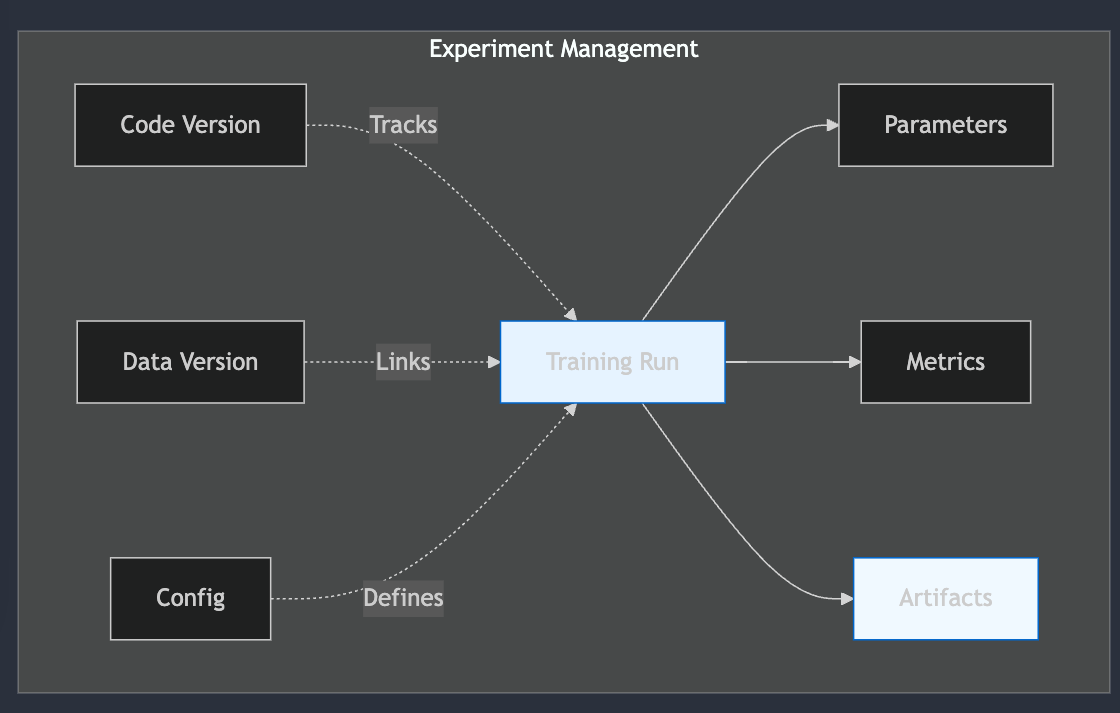
Let's understand what this system tracks:
Parameters (Input Configuration)
Model architecture choices
Training hyperparameters
Data preprocessing settings
Environment configurations
Metrics (Output Measurements)
Model performance scores
Training time and resource usage
Validation results
Custom metrics for your use case
Artifacts (Generated Files)
Trained model files
Validation reports
Performance visualizations
Debugging information
Here's a conceptual example(python) of tracking an experiment:
# Conceptual example of experiment tracking
with mlflow.start_run():
# Track inputs (like build parameters)
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("model_type", "RandomForest")
# Track outputs (like build results)
mlflow.log_metric("accuracy", 0.95)
mlflow.log_metric("training_time", 120)
# Save artifacts (like build artifacts)
mlflow.sklearn.log_model(model, "model")The key difference from CI/CD tracking:
Multiple successful runs are normal (unlike builds where you want one success)
Need to compare runs against each other
Experiments might run for hours or days
Results can be non-deterministic
3. Model Registry
Think of this as your artifact repository (like Artifactory or Nexus) but specialized for ML models:

Model Serving Architecture: Making ML Models Available
As a DevOps engineer, you're familiar with deploying applications to serve user requests. Model serving follows similar principles but with unique considerations. Let's explore this architecture:

Let's break down each component of this serving architecture:
Model Server
Think of this as your application server, but optimized for ML workloads. It handles:
Efficient model loading and unloading
Batch prediction capabilities
Resource optimization for inference
Model version management
Here's what model serving might look like conceptually(python):
# Conceptual example of model serving
class ModelServer:
def __init__(self):
self.model = load_model_from_registry("model:latest")
self.preprocessor = load_preprocessor()
async def predict(self, input_data):
# Preprocess incoming data
processed_data = self.preprocessor.transform(input_data)
# Make prediction
prediction = self.model.predict(processed_data)
# Format response
return format_prediction(prediction)
API Gateway Layer
This layer should feel familiar, but with ML-specific concerns:
Input validation becomes crucial (garbage in = garbage out)
Response formatting might include confidence scores
Request batching for efficiency
Version routing for A/B testing
MLOps Monitoring: The Complete Picture
In MLOps, monitoring expands beyond traditional operational metrics. You're not just watching system health; you're monitoring model performance and data quality:

Let's examine each monitoring dimension:
System Metrics (Familiar Territory)
Resource utilization (CPU, memory, GPU)
Latency and throughput
Error rates and system logs
Network metrics
Model Metrics (New for MLOps)
Prediction accuracy
Model confidence scores
Inference latency
Prediction distribution
Data Metrics (Also New)
Feature drift detection
Data quality scores
Missing value rates
Distribution shifts
Here's a conceptual example (python) of a comprehensive monitoring setup:
# Conceptual example of MLOps monitoring
class MLOpsMonitoring:
def collect_metrics(self):
return {
# Traditional metrics you know
'system': {
'cpu_usage': get_cpu_metrics(),
'memory_usage': get_memory_metrics(),
'latency': get_latency_metrics()
},
# New ML-specific metrics
'model': {
'accuracy': calculate_accuracy(),
'drift': measure_prediction_drift(),
'confidence': get_confidence_metrics()
},
# Data quality metrics
'data': {
'completeness': check_data_completeness(),
'drift': measure_feature_drift(),
'quality': assess_data_quality()
}
}
Deployment Strategies in MLOps
ML model deployment adds new considerations because model behavior can be unpredictable with real-world data:
Todo: Elaborate on the deployment models.
Resource Management: Balancing ML Workloads
Managing resources in MLOps brings new challenges. You'll deal with both training workloads (intensive but temporary) and serving workloads (continuous but variable):

Key considerations for resource management:
Training Resources
GPU allocation and scheduling
Distributed training coordination
Temporary but intensive workloads
Cost optimization for expensive resources
Serving Resources
Efficient CPU utilization
Auto-scaling for variable load
Memory management for model serving
Batch processing optimization
Error Handling in MLOps: Beyond Traditional Failures
As a DevOps engineer, you're used to handling system failures and application errors. In MLOps, we need to handle those plus an entirely new category of ML-specific issues. Let's explore this expanded error handling landscape:

Let's examine each type of error and its handling strategy:
Input Errors
Just like in traditional applications, but with ML-specific considerations:
# Conceptual example of ML input validation (python)
def validate_prediction_input(data):
try:
# Traditional checks
if not data:
raise ValueError("Empty input")
# ML-specific validation
if not check_feature_completeness(data):
raise MLFeatureError("Missing required features")
if not check_feature_ranges(data):
raise MLFeatureError("Features outside training range")
return True
except Exception as e:
# Log and handle appropriately
logger.error(f"Input validation failed: {e}")
return handle_validation_error(e)
Model-Specific Errors
These are unique to ML systems and require special handling:
Low confidence predictions
Out-of-distribution inputs
Resource constraints during inference
Model serving timeouts
Here's how you might handle these:
# Conceptual example of ML error handling (python)
class MLErrorHandler:
def handle_prediction(self, model, input_data):
try:
# Make prediction
prediction = model.predict(input_data)
# Check prediction quality
if not self.is_prediction_confident(prediction):
return self.handle_low_confidence(prediction)
if self.is_out_of_distribution(input_data):
return self.handle_outlier(input_data)
return prediction
except ModelTimeout:
return self.fallback_strategy.get_prediction()Getting Started: Your MLOps Journey
Now that we've covered the key concepts, let's talk about how to begin your MLOps journey. Remember, just as you didn't learn all of DevOps in a day, MLOps mastery comes through progressive skill building:

Progressive Learning Path
Start with familiar territory:
Use your existing CI/CD tools
Deploy simple ML models
Implement basic monitoring
Add ML-specific components:
Experiment tracking
Data version control
Model performance monitoring
Advance to complex patterns:
Automated retraining
A/B testing
Advanced serving architectures
🚀 Ready to Put Theory into Practice?
Understanding these concepts is just the beginning. Ready to build real MLOps pipelines? Join our upcoming "30-Day MLOps Challenge" where you'll create an end-to-end MLOps system, applying everything you've learned in this guide.
In the challenge, you'll:
Deploy real ML models
Set up monitoring systems
Implement automated retraining
Build production-grade pipelines
Stay tuned for the challenge announcement or join our waiting list!
Looking Ahead
In Part 2 of this series, we'll dive deep into ML pipelines, exploring how they differ from traditional CI/CD and how to build them effectively. We'll see how your pipeline expertise translates to training workflows and model deployment processes.
Remember: Your DevOps background is a powerful foundation for MLOps. Every concept we've covered builds on principles you already understand, just adapted for the world of machine learning.
💡 Key Takeaway:
MLOps is an evolution of your DevOps skills, not a revolution. Take time to understand how each new concept relates to your existing knowledge, and you'll find the transition natural and manageable.
Tags: #MLOps #DevOps #ML #Engineering #Development